OpenResty Edge™ Overview
Overview
This document describes the requirements of the OpenResty Edge commercial product provided by OpenResty Inc.
This document also defines the terminology needed for efficient communications inside OpenResty Inc. and between OpenResty Inc. and its customers. Not every feature documented in this document has been implemented in the current version of the OpenResty Edge product. When in doubt, please contact the OpenResty Inc. company for details.
Not all the important features are documented here. This document is only meant for a quick overview of the whole product.
Goals
OpenResty Edge is a platform based on the OpenResty open source web platform for setting up dynamic load balancers and reverse proxy clusters. The whole product or at least some core components of it can be used by either Content Distribution Networks (CDNs) and other web-based businesses for their web gateways and traffic entries.
Even though OpenResty is built atop NGINX and LuaJIT, no prior knowledge about NGINX and/or Lua is required by the OpenResty Edge product users. Most of the common configurations and operations can be done easily in a web UI (or REST API and SDK) without any coding or configuration file edits. It is designed to easily control and manage a big network of machines in a single central web controller.
Advanced users with complicated custom needs can also specify ad-hoc rules in the Edge domain-specific language and the Admin portal will automatically compile the rules into highly optimized Lua, C, and other JIT-able code and push them across some or all of the server machines (or gateway nodes) on the Gateway Network (aka the edge), either public clouds or private clouds or their mix.
All the standard features and web forms in the OpenRest Edge web console also result in Edge language rules which enjoy exactly the same optimizations based on specializations.
Tech-savvy users can further extend and/or customize the OpenResty Edge platform by writing Lua or C code, like introducing custom Lua libraries for OpenResty or loading custom NGINX C modules.
Edge Admin Site & Log Server
We define Gateway as groups (or Clusters) of machine nodes facing directly to the outside world, i.e., the Internet (or all the end-users in case of a private Intranet). In the terminology of the CDN industry, the Gateway Network is usually called the edge. Since the word “edge” is already heavily loaded with many meanings in OpenResty Edge, we will just use the term Gateway Network or just Gateway exclusively in this document. The Gateway Network can be deployed on public clouds like Amazon Web Services and Google Cloud Platform, or private data centers or colocations with the customer’s own metals.
We define the Admin site as the central machine node or nodes running the admin site (or web controller) of OpenResty Edge. We do allow multiple web Admin nodes to be deployed, but these Admin site nodes all share the same backend database (be it PostgreSQL or MySQL) or database clusters in the backend. The Admin site usually does not run on the Gateway Network but in Users’ own private networks (LANs). It is still possible to deploy the Admin site in a Gateway Cluster and share the same machine or machines in the Gateway Network.
The Admin site accepts instructions or configurations from the User and pushes any changes to the Gateway machines directly or indirectly in a soft real-time fashion.
Gateway nodes are grouped in terms of Gateway Clusters, or just Clusters. See below for more details about Clusters.
the Gateway nodes connect to the Admin site through encrypted connections (TLS protected) to communicate. The Admin site listens on a special TCP port. A randomly generated or user-supplied SSL server and client certificate pair will be used across the Gateway nodes to authenticate the Admin site client. New Gateway nodes must be approved on the Admin site to join a particular Gateway Cluster in the Gateway Network.
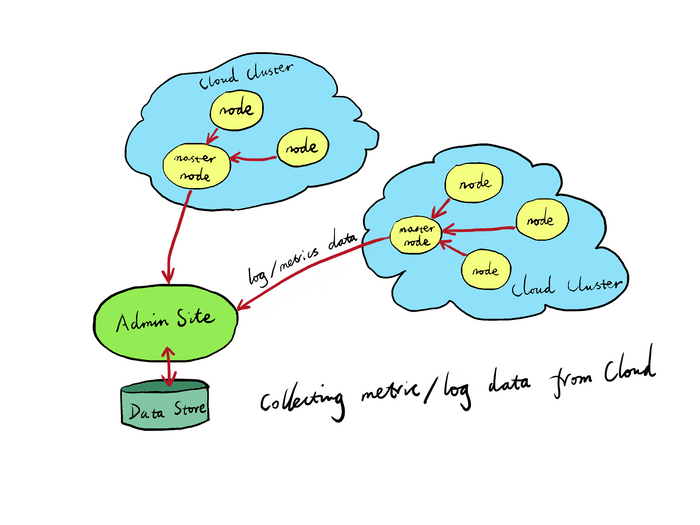
The Gateway nodes also connect to a special Log Server to feed error log and metrics data at real-time.
Instead of making the Admin site talk to all the Gateway nodes directly, it can also be configured in the Cluster settings to make Admin only talk to one or more “master nodes” of each Cluster. And then the master node of each Cluster will propagate the configurations to the rest of the nodes in the same Cluster accordingly. This way, we do not need to open up access to all the Gateway nodes for the Admin nodes, but just those “master nodes”. In this setting, each Cluster must have at least one “master node”, but may also specify multiple “master nodes” for redundancy. (Note: this is still to be implemented. Right now, all Gateway nodes talk to the Admin site directly.)
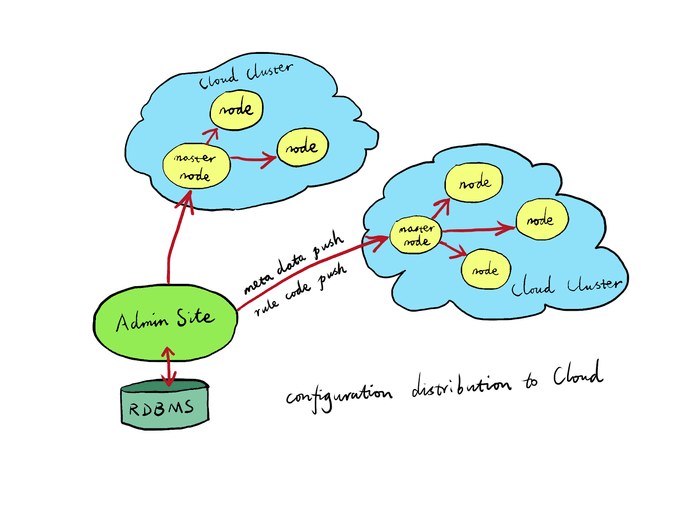
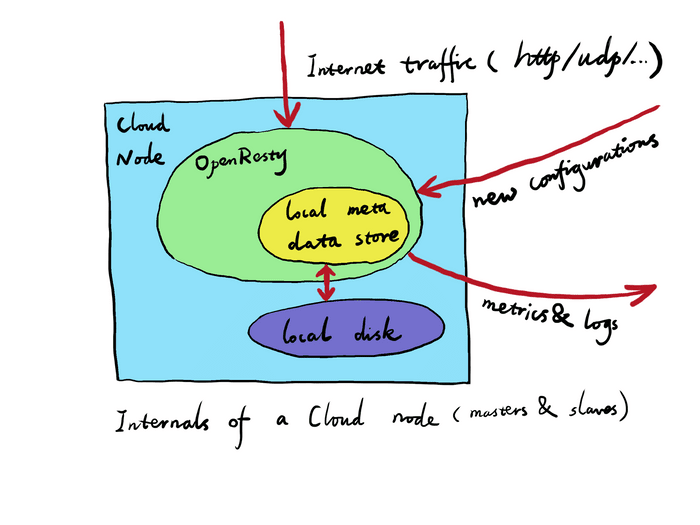
Each Gateway node’s OpenResty/NGINX processes have their own persistent storage backend based on Lightning Memory-Mapped Database (LMDB) for any configurations pushed by the Admin site or the master node of the current Gateway Cluster so far. For this reason, even when a Gateway node is put offline for a while and goes online again, it will only need to pull from the master node of the current Gateway Cluster and synchronize any new configuration changes since the last time it goes offline. Such newly-online Gateway nodes automatically synchronize the configuration code and data from the master node of the current Gateway Cluster. If it is the master node going online, it should synchronize either from some other node in the same Cluster or from the Admin site directly (if there is a network route in that direction).
Because each Gateway node has its own local persistent storage for all the configuration data (or meta data), it can serve its own Internet traffic perfectly fine even when the Admin site or the master node of the current Cluster goes offline or are just unreachable. The Gateway node may just not be using the latest version of the configuration data in such abnormal conditions. In other words, each Gateway node is self-contained.
The Log Server will also collect log data from all or some of the Gateway nodes. It can be configured in a similar way but in a reversed direction. That is, all the Gateway nodes will send access log and error log data to the current master node in the current Gateway Cluster, and the master node of each Gateway Cluster will send the data back to the Log Server. The User can configure it in such a way that only aggregated access log data is leaving the Edge slave and master nodes, which can significantly reduce bandwidth usage for data collections. Similarly, error logs can also be aggregated on the Edge by merging similar ones.
The Log Server is usually deployed in dedicated servers different from the Gateway nodes and Admin site.
The Admin site controls what kind of data to be collected on the Gateway and how those data should be interpreted. So the Admin site tries hard not to collect data that is not needed for the current user configurations and can always add probes to each of the Gateway nodes to collect more data if the User asks for more. Everything should happen automatically without touching any of the Gateway nodes manually by the User.
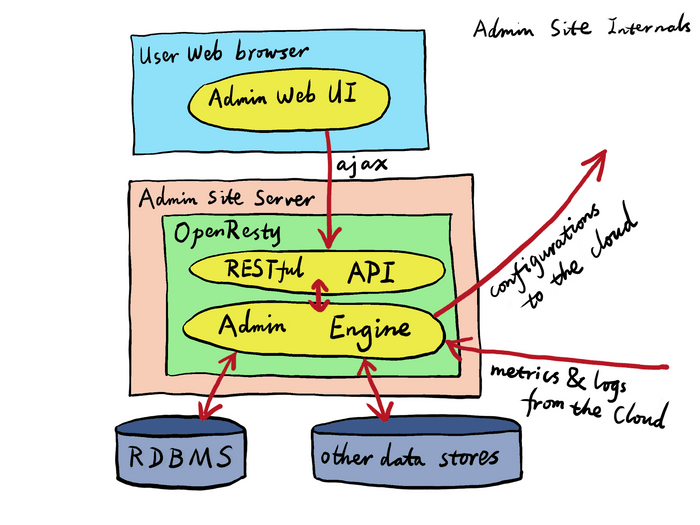
The Admin site’s web UI runs completely in the User’s web browser while the web UI talks to the Admin site’s server through a RESTful API (PHP and Python SDK are available). For this reason, the User can integrate the Admin site’s functionality into its own Web UI or her own tool chains like command-line utilities or custom web applications to automate the Admin site operations to fit her own needs.
The User can show a snapshot of the current Application configuration (or on the top of an earlier revision) in a human-readable report. This report can be saved as an external plain text file and can later be imported and restored to the corresponding configuration in the Admin site. (Note: this is still to be implemented.)
Server Reloading & Hot Code Replacement
For most of the configurations pushed by the Admin site to the Gateway, it does not require server reloads on the Gateway nodes. Rather, it performs hot code and data replacement inside each individual server process. For example, there is no HUP reload incurred to the NGINX processes for most of the configuration and code updates. And most of the code is replaced safely on the fly, without replacing existing NGINX worker processes with brand new ones (which typically happens with a HUP reload operation against an NGINX daemon). This means that it has zero impact on existing long-running client and upstream connections, and a configuration push for a particular Application has no impact on other Edge Applications running inside the same NGINX worker processes across the Gateway Network.
There are still a small set of configuration changes that do require a server reload or restart operation, like adding a new Application with a brand new listening port (or service port). In such cases, the Admin site will notify the user about the server process reload requirements on the web UI and will schedule the reload automatically across the target Gateway nodes in an incremental manner. Only Super Users can push changes that require server reload or (0-downtime) restart. And such Users can also choose a specific plan to carry out such Gateway reloads and restarts in an orderly manner to minimize online impact.
The Admin site can also send orders to the Gateway nodes to do a self-upgrading of the whole OpenResty Edge product. For obvious reasons, such software upgrades also require a full server restart operation.
Daemons & Processes
The OpenResty Edge product only runs the NGINX processes of OpenResty on both the Gateway Network and the Admin site. In addition, the Admin site requires a relational database (PostgreSQL or MySQL) to serve as the backend. Unlike the Admin site, the relational database system does not need to run on the Gateway Network.
Besides the OpenResty/NGINX processes (in both the Gateway Network and the Admin site) and the relational database processes for the Admin site, There is no FastCGI or any other daemons required to run.
The OpenResty/NGINX processes in the Gateway Network can also speak Memcached or Redis wire protocols and uses NGINX’s shared memory storage, with an optional LMDB disk-based backend. This means that the same OpenResty processes can serve as a distributed memory cache system without extra daemon processes. And such caching endpoints can enjoy the same flexibility provided by the rest of the OpenResty Edge product, including flexible metrics and Edge language scripting.
Applications
An Application is a collection of configurations for one or more domain names with a set of service ports.
An Application is designated by at least one domain name, like api.foo.com, for a wildcard domain name like *.foo.com to include both foo.com and all its subdomains.
An Application can also take an optional set of service ports (or listening ports) to be even more special. For example, api.foo.com:8080 can be a special Application for internal API services, which can be separated from the public services at api.foo.com:80.
An Application can choose from one of the following service protocols (i.e., wire protocols used to serve clients):
- HTTP/HTTPS
- TCP
- UDP
- DNS
The service protocol defines the type of the Application. It also defines the default service ports used by the Application. For instance, HTTP usually uses the 80 port while DNS usually uses the 53 port.
Applications are a concept very much like “virtual hosts” or “virtual servers” in the terminology of HTTP server software like Apache httpd and NGINX.
Applications define the smallest granularity of OpenResty Edge configurations. Each Application has separate configurations though an Application can choose to inherit configurations from another Application and only define its own overriding configurations incrementally.
Application inheritance can be a simple snapshot of the “base Application” at the time of creation of the “child Application” or always follow any new changes of the “base Application” throughout the lifetime of the “child Application” since its creation. Application inheritance usually happens when a new subdomain wants to inherit all the existing configurations of the root domain, like api.foo.com vs foo.com. It’s a handy way to share common configurations across different subdomains in a website.
When you login into the Admin site, the User has to enter her user account name and password, and also choose which application she wants to work with. Alternatively, the logged-in User can create a new Application by specifying its domain name and an optional listening service port number (or multiple port numbers).
Gateway Clusters
Gateway Clusters or just Clusters are groups of machines on the Edge (see the definition of Edge above). The Admin site tends to manage all the machines across the Gateway Network. The Admin site itself may also consist of a cluster of nodes, but the Admin site does not (usually) run in the Gateway Network.
The User needs to enter all the machine details (like hostnames) himself in the central Admin site, and group them according to their physical locations or other custom criteria.
Gateway Cluster machines can be shared among different Applications if enough permissions are granted to the Application Users. So naturally, multiple Users can also see the same Gateway Cluster information.
Users & Roles
Users are login accounts of the Admin site. Each User can be assigned one or more “roles”. A role is a set of access rules that can be applied to a User. For example, we can have a User Admin role and Super Admin users. And Super Admin users can create more users and assign them different access permissions and/or roles. A Super Admin role has the access to all operations supported by the Admin site. And we call Users of the Super Admin role _Super User_throughout this document.
For example, a User with enough permissions can create read-only roles for an Application (or several Applications). Also, the User can define a role that can only configure a particular Application.
Generally, only Super Users can push configuration changes that require server reloads or restarts on the Gateway Network. Normal Users still can make such configurations but they just cannot push them.
Revisions & Releases
The Admin site has built-in version control support for most of the gateway configurations. We use our own enhanced algorithms derived from the latest academic research in the patch theory discipline.
When the User stops changing a configuration (no matter how small it is), then a new revision is generated on top of the current configuration change sets in the Admin site. Revisions that are never released are called pending changes.
The User can also create a Release including all the pending changes. Releases are just tags on revisions per se.
The User is free to restore (or roll back to) any historical releases. He is also free to push the current revision to all the Gateway nodes visible to the current Application or just a specified subset of Gateway nodes or Gateway Clusters. Such subsets of Gateway nodes for different released configurations are called partitions. Such partitions are usually used for separating outside and inside web applications for an enterprise customer or reserving a dedicated group of nodes for A/B testing of new configurations (or customers’ own backend applications).
The User can compare different revisions and the Admin site will give a human-readable presentation for the changes. The revision history itself is always read-only.
A warning message should be displayed on the Admin web UI when multiple Users are trying to edit the same Application at the same time. (Note: this is still to be implemented.)
Testing
The Admin site allows the User to create custom test cases for issuing test requests to all or a selected subset of the Gateway nodes and automatically check the responses according to User-defined criteria. Two different ways are allowed:
- Use web forms to specify the request URI, method, body, headers, etc, as well as the expected response features, like a 200 status code, presence of some keywords in the response body, a particular value of the Content-Type response header, and etc.
- Use the TestML domain-specific language to specify many such test cases easily in a Web-based code editor (or even a full-fledged web IDE).
See below for more details on the TestML language:
The tests are part of the Admin site configurations and are also subject to versioning through Revisions and Releases.
A dedicated group of Gateway nodes (called a partition) can be configured for A/B testing.
The test cases can be used to initiate load testing against a particular Gateway node selected by the User. The User can specify the total number of requests to be sent as well as the number of concurrent connections used in the load testing. Similar to Apache httpd’s ab tool but all inside the Admin site. The load test report can report the throughput (req/sec, bytes/sec) and also request latency. Such benchmark results will also be kept inside the current configuration revision for future references and comparisons.
It is also possible to test new configurations with real traffic but without any consequences on real client users. The Admin site User can configure some specific Gateway nodes (called a Gateway partition) to automatically duplicate some or all of their incoming traffic and redirect the duplicated traffic to some offline Gateway Clusters dedicated for testing. Those online Gateway nodes will also silently and asynchronously drop any responses from those offline Gateway Clusters. This is similar to tools like tcpcopy but works directly on the L7 level inside the OpenResty/Nginx processes. Unlike L4 traffic duplication tools such as tcpcopy, OpenResty Edge’s L7 approach can also work with SSL traffic without any problems. (Note: this is to be implemented.)
Edge Language
OpenResty Edge provides a domain-specific language called Edge (or edgelang) for the Users to script complicated rules and business logic directly for the Gateway nodes.
The Edge language is a rule-based language that allows specifying rules to be run on the Gateway.
The User enters her Edge language rules directly through the Admin site (via a web code editor) and the Admin site compiles this Edge language source code into optimized Lua code and data, and then pushes the resulting Lua code and data to the Gateway nodes directly or indirectly.
The Admin site also provides web forms for the User to add simple rules without knowing the Edge language or doing any scripting.
The Edge language rules are also part of the Application configurations and also subject to version control through revisions and releases.
Under the hood, many of the standard Admin functionality modules are also implemented in the Edge language (or templates of Edge language code).
The Admin site provides a simple web-based IDE for Edge language scripting and debugging. This can be integrated with the test suite specified in TestML mentioned in the Testing section above.
It is also supported to use Perl’s TT2 templating language syntax inside the Edge language source code, essentially creating template-ized Edge language programs. The Admin site can automatically generate RESTful APIs and new web UIs from these Edge code templates allowing the User to reuse these templates in the future by feeding parameter data into these templates. Additionally, the templating layer, like a macro layer, can be used to generate many similar but still different Edge language rules without code duplication. Future versions of edgelang may employ a full-fledged integrated macro language feature without any preprocessor-like templating layers.
Advanced Users can customize and/or extend the Edge language by defining their own predicate functions, action functions, and other primitives on the Edge language level. No changes to the Edge language compiler are needed. The User can use the Edge language to define new primitives or even new Edge libraries himself. Super Users can even invoke external Lua routines or libraries from within the Edge language. Invoking external C library API is also supported through the external Lua calls since LuaJIT supports calling arbitrary external C API via its standard FFI extension.
It is also possible for the Super User to define Edge language rules to be run inside the Admin site to automate the distribution of Gateway rules and data across the Gateway based on real-time metrics from the Gateway.
Please refer to the Edge Language User Manual for more details.
SSL Servers
We will use the term SSL throughout this document even when TLS is more appropriate.
The User can add SSL certificates and private keys for the SSL servers in the current Application through the Admin site and push them along with the rest of the Application configurations.
The User can configure SSL session data sharing (for SSL session IDs only) across the current Gateway Cluster nodes (inter-Cluster sharing would require asynchronous data distribution like Datanet, otherwise the latency would be out of control). SSL session data sharing is important for older HTTPS clients that do not support TLS session tickets and can significantly reduce the number of expensive SSL handshakes.
The User can configure what kinds of SSL protocols and SSL ciphers are allowed for the current client SSL connection unconditionally or conditionally. Whether to enable OCSP stapling and strict OCSP stapling validations.
For Applications enabling HTTPS, a randomly generated TLS session ticket key will be periodically distributed by the Admin site to all the Gateway nodes (or to the master nodes of the Gateway Clusters). The TLS session ticket keys will be generated every hour, which can be configured to any other time period. An array of up to 12 TLS session ticket keys will be maintained throughout the Gateway nodes. Older session ticket keys will simply phase out and be discarded. The size of the maintained TLS session ticket keys is also configurable. So the User can choose to keep all the keys generated in the last 24 hours, for example, when he sets the array size to 24 and the new key period to 1 hour. TLS session tickets are also crucial to reducing expensive SSL handshakes on the Edge. And it is important to share the session ticket keys across the Edge.
Soft real-time data analytics can also be enabled or disabled by the User to analyze SSL session resumption rates (on either SSL session IDs or TLS session tickets), SSL protocol use distribution, SSL cipher usage distribution, and other metrics on the Edge.
Custom rate-limiting and concurrency limiting rules can also be specified in SSL handshake requests, either by web forms or by custom Edge language rules. Predefined or custom online metrics can be configured for traffic control’s actual effects.
HTTP/2 can also be configured by the User.
WAF
OpenResty Edge provides a Web Application Firewall (or WAF) product mainly based on ModSecurity’s Core Rule Sets (or CRS). These CRS rules are implemented as Edge language rules under the hood but were generated from their original ModSecurity configuration files.
WAF rules can be enabled or disabled by ruleset modules, or by individual rules. Soft real-time data analytics are also provided for requests hit by some WAF rules for the User to analyze malicious requests on the Edge.
The User can also add new WAF rules by submitting web forms or directly adding new Edge language rules. Alternatively, the User can edit existing WAF rules by either editing web form fields or the underlying Edge language source code.
Custom rules to only enable WAF on certain client requests are also supported, like only enabling WAF on POST requests, or only on URLs with certain patterns.
The User can configure actions taken when a request is blocked or denied by the WAF. For example, the user can choose to show a custom error page with a captcha challenge. Once the client passes the captcha challenge, a special cookie is planted to give the client a free pass for a configurable time period. Small client requests blocked by the WAF can also be cached temporarily on the server-side and can be automatically replayed once the client passes the captcha challenge within a specified period of time.
Request Filtering & Rewriting
The User can specify custom rules (either via web forms or Edge scripting) to filter out and/or to rewrite certain client requests served on the Edge.
For example, the User can inspect and/or rewrite the URL path, to rewrite the URL query-string or individual URI arguments. The User can also rewrite request methods, request headers, cookies, and request body data (including URL encoded POST arguments) with ease.
The User can choose to do a redirect (like 301, 302, and 307 redirects) when certain criteria meet on the current client request, or just serve out a custom error page or abort the connection directly.
Geographical information derived from the client IP addresses can also be used in user rule conditions, like filtering out clients from a particular city, country, or region.
Automatic data analytics can also be provided automatically for the User request filtering or rewriting rules if the User enables them. Corresponding data collection code will automatically be deployed into the Edge at the same time for each User rule so that the user can see how many times a particular rule has got hit (and missed) on the Edge at soft real-time and concrete request samples actually hitting that rule.
Rate limiting, traffic shaping, and concurrency control can also be enabled in this phase. The User can configure limits on different criteria and/or granularities at the same time, for a single request.
Initial versions of OpenResty Edge will do traffic limiting on the instance level (though across all the NGINX worker processes). Future versions will also support Cluster level or even global level traffic limiting through CRDT algorithms.
Response Filtering & Rewriting
Similar to request filtering and rewriting, these User rules can apply to responses.
Eventually we can allow the User to specify Perl-compatible regular expressions to do streaming substitutions in potentially very large response bodies fulfilling some criteria, similar to the open-source ngx_replace_filter NGINX module, but much more flexible and dynamic, and also much faster.
OpenResty Edge incorporates OpenResty Inc.’s own proprietary regular expression engine, sregex2, that guarantees to deliver O(n) time complexity (where n is the length of the data stream) and O(1) space complexity (when the regular expression pattern is fixed). The sregex2 engine may also be utilized by other request filtering facilities like the WAF introduced above.
Here we can also provide predefined filters like conditional or unconditional Gzip compression, simple CSS/HTML/JavaScript minification (just removing unnecessary spaces and comments from the response on the fly and streamingly) on dynamic contents with sregex2.
Automatic metrics and analytics can also be enabled or customized in this context.
Output data rate limiting can also be applied on the response level conditionally or unconditionally, and can also change dynamically in a single response, like only limiting after sending out 1MB of response data in a single response.
Static Resources
The User can submit static resources to be served by the Edge. The user can choose to serve these resources directly from the Edge machine memory, which is always the fastest way, or for large static resources which are too big to fit into RAM as a whole, can be stored on the local file system of each Gateway node.
Static gzip resources can also be supported at the same time.
Reverse Proxy & Load Balancer
The User can configure origin servers (or backend servers) for the reverse proxy or load balancer to run on the Edge. Each server has a hostname, machine ID, service ports, etc.
Predefined load balancing policies like weighted round-robin, weighted consistent hashing, modulo hashing, and least connections are provided and the User can choose one from them.
The User can define their own ad-hoc load balancing rules via web forms or Edge scripting.
The backend servers can be toggled up and down when a specified number of successive failures are detected. Automatic backend retry policies can also be specified or customized. For example, when 500 happens, automatically retry another backend server according to some rules.
Timeout settings on each backend server can be specified, like connect, read, and send timeout thresholds. They can be on the request level and can be conditional.
Proactive health checks on the backend servers can be enabled. The User can configure custom health-check requests and complicated response checks.
The load balancer and reverse proxy facility are integrated by the Edge language. And it can support tiered caching and request routing for complicated multi-layer CDN-like networks.
Cache
We can allow configurations of NGINX’s HTTP cache which is based on the file system and files. Various common NGINX proxy_cache configurations should be exposed to the Admin web UI.
The User can also choose to enable the subrequest-based cache provided by the ngx_srcache module so that the responses will be cached by external Memcached or Redis services.
Eventually OpenResty Edge will ship with its own CDN-level cache software based on OpenResty, which can efficiently handle both huge data streams (like videos) and tiny data fragments (like small JSON responses for APIs).
Soft real-time cache purge requests can also be submitted by the User through the Admin site. For example, the User can specify URI patterns or other custom conditions to purge the cached versions of those matched requests across the Gateway Clusters.
Distributed caching across nodes in each Gateway Cluster can be configured. The User can also choose from a predefined set of hashing policies like weighted consistent hashing, weighted modulo hashing, weighted round-robin, and least connections. Additionally, the User can specify her own hashing algorithms or exception rules with either the simple web forms or Edge language scripting.
The OpenResty Edge product can also be configured to work with Users’ own cache software, even those having nothing to do with NGINX or OpenResty.
DNS
OpenResty Edge does not only provide an HTTP/HTTPS server, but also a DNS server supporting both UDP and TCP transports.
OpenResty DNS also runs on the Gateway and can even share the same Gateway nodes with other HTTP/HTTPS/TCP/UDP typed Applications. They can even share the same OpenResty/NGINX server processes.
Each DNS service has its own Application. The DNS service Application can be referenced by other HTTP/HTTPS/TCP/UDP Applications. Each HTTP/HTTPS/TCP/UDP Application can choose to take a seat in a specified DNS service run on the Edge. The Gateway Clusters used to run the DNS service is configured separately in DNS’s own Application, which can be different from the Gateway Clusters associated with the current Application for HTTP/HTTPS services.
The same applies to raw TCP/UDP typed Applications.
The User can define various DNS records for the domain names associated with the current Application. Those records can be conditional, based on complicated prerequisites like the origin of the DNS requests and the current timestamps.
Advanced DNS features like DNSSEC are also planned. In the future, an alternative userland networking implementation based on DPDK or Snabb can be enabled in the OpenResty DNS server to bypass the operating system’s network stack altogether, which can usually lead to better performance.
TCP/UDP Servers
Similar to HTTP/HTTPS servers, but just proxying or load-balancing arbitrary TCP or UDP traffic. So concepts specific to HTTP/HTTPS like request URIs and request headers do not apply to this context.
An Application can choose its type to be either the TCP or UDP during its creation process.
Error Logs
The Gateway nodes can generate NGINX error logs. These error logs are collected in a similar fashion as the access logs and should be collected upward to the Admin site in (soft) real-time.
The Admin site can automatically map the error logs to the corresponding panels or even rules in the user configurations of the corresponding revision. The Admin site automatically generates tags or identifiers in any predictable error messages so that Admin can later do the mapping automatically without human assistance.
The Admin site also gives human-friendly explanations and even suggestions on common NGINX error log messages. Some suggestions can even lead to online tracing analysis provided by the Trace subsystem (see below for the Trace section).
The User can write her own error log classifiers and counters which the Admin site will automatically execute.
Tracing & Debugging
The Admin site can instruct a specified Gateway node (or even the Admin site node) to dynamically trace its own service processes for online performance profiling and/or troubleshooting. Dynamic tracing tools based on SystemTap, Linux eBPF, or alike will be used so it can be safely used online, with real production traffic.
An on-CPU flame graph can be generated from a trace command for analyzing high CPU usage in a particular Gateway node. Similarly, an off-CPU flame graph can be generated to analyze NGINX worker processes that are blocked a lot. The Admin site can provide actionable suggestions by automatically analyzing the resulting flame graphs, for example. And other Trace tools can provide a lot more runtime details about the whole software stack way down to the Linux kernel.
Offline analysis on core dump files of the OpenResty/NGINX processes (or even other exotic processes) can also be carried out through the Admin site. This is useful for automatically analyzing online crashes or just process space snapshots of a still-running OpenResty/NGINX worker process on a particular Gateway node or nodes. Like online analysis, such offline analysis leverage advanced tools (based on GDB or LLDB) shipped with OpenResty Edge.
Most of the online and offline analysis tools will give actionable suggestions to the User for either optimizations or bug fixes.
The User can choose to submit the online and offline analysis reports to OpenResty Inc.’s engineering team for further analysis.
The Admin site also provides the Y language, a domain-specific language for universal debugging and tracing, to create custom dynamic tracing tools that can be enabled on-the-fly across the Gateway Network. The Y tracing programs can be compiled to Systemtap scripts or even GDB Python scripts for both online analysis (using Systemtap) and also offline core dump file analysis (using GDB). But only super User can supply their own tracing tools using the Y language.
The Edge language scripts and most of the core modules of OpenResty Edge come with a special debugging mode, with which the User can gather detailed debugging information for a particular abnormal request. The debugging mode does slow down the online processing, for obvious reasons, and can be toggled by the User through the Admin site only on demand.
API Filters
The Admin site allows the User to provide JSON schema and SchemaType to specify data structure definitions for JSON/YAML/CSV data streams (either in request bodies or response bodies, the former is usually more useful). These data formats are often used in RESTful APIs or other web services.
See http://www.schematype.org/docs/home/ for more details on SchemaType.
The Admin site can also allow the User to write jq language code to do JSON data transformations in the HTTP/HTTPS reverse proxies. Jq is a domain-specific language for transforming structural data streams like those in JSON. See below for more details on the jq language:
https://stedolan.github.io/jq/manual/
Serverless Scripting
The User is allowed to use a subset or dialect of Perl 6, JavaScript, Python, or PHP to write simple web applications that can run directly on the Edge. The Admin site provides a simple web IDE for scripting content handlers in one of those general-purpose languages or for implementing ad-hoc functions that can be used in the Edge language scripts.
These general-purpose language subsets or dialects will be compiled to highly-optimized Lua code just like the Edge language. And a “compile-time sandbox” is employed to ensure that such scripts won’t run for too long or eat up too much memory than configured.
Such general-purpose scripts are certainly much less efficient than Edge language scripts.
Note: this is to be implemented though we already have a Perl 6 dialect implementation called fanlang, which has been heavily used by the OpenResty Inc team to build the Edge product itself.
Metrics & Data Analytics
Every Edge language rule and predefined feature in the OpenResty Edge product can have soft real-time metrics. Many predefined product features come with built-in metrics that can be toggled on the Admin site. The User is free to define her own metrics by tagging an Edge language rule or a condition on a specified Edge language rule or writing dedicated Edge language rules to create custom metrics. The metric data is collected using the same data pipeline as the access and error log data, feeding back to the Admin site as aggregated results like sums, counts, averages, etc. These metric results can be used to feed and drive Edge language rules run in the Admin site to automatically control the Gateway Network in some ways dictated by the Super User, like using Gateway’s real-time metrics to automatically direct routing and load-balancing policies in the corresponding Gateway nodes or Gateway Clusters.
OpenResty Edge provides a full-fledged data analytics platform that can do common and also custom complicated analyses and aggregations on historical and real-time access log data with complicated data reporting and data visualization methods and a web interface to access everything.
A SQL-like domain-specific language, named ORSQL, can be used to create custom data queries that will execute in a distributed manner. Note: this is to be implemented.
Everything still runs atop the OpenResty tech stack.
The User can choose, however, to feed the online log data streams into other 3rd-party data analytics or log processing systems.